YOLO v4
Introduction
- 开发了一个简单且高效的目标检测算法,该算法课通过普通的GPU(1080Ti或2080Ti)进行训练
- 作者验证了在目标检测算法的训练过程中不同的技巧tricks对实验性能的影响,这些tricks主要包括Bag-of-Freebies和Bag-of-Specials
- 作者修改了一些state-of-the-art的算法,使得这些算法适用于单GPU上训练,这些算法包括了CBN,PAN和SAM等等
Related Work
现代检测器的整体架构
现代的检测器一般都由两部分组成,第一部分是在ImageNet上经过预训练的Backbone,第二部分是用来预测物品种类和边界框的Head。对于近年来出现的目标检测器,它们一般是在Backbone和Head之间插入一些层,这些层通常用于从不同阶段收集特征图,这一些层,我们将之称为Neck。
1.Backbone
在GPU平台上Backbone更多使用VGG、ResNet、ResNeXt、DenseNet、Inception、EfficientNet、CSPDarkNet,在CPU平台上Backbone更多使用SqueezeNet、MobileNet或Shuffle。
2.Head
对于Head,一般有两类:单阶段目标检测器和双阶段目标检测器。
1.单阶段目标检测器(Dense Prediction)
- RPN, SSD, YOLO, RetinaNet (anchor based)
- CornerNet, CenterNet, MatrixNet, FCOS (anchor free)
2.双阶段目标检测器(Sparse Prediction)
- Faster R-CNN, R-FCN, Mask RCNN (anchor based)
- RepPoints (anchor free)
3.Neck
通常Neck由几个自下而上的路径和几个自上而下的路径组成。
- Additional blocks: SPP, ASPP, RFB, SAM
- Path-aggregation blocks: FPN, PAN, NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
Bag-of-Freebies
Bag of Freebies 在目标检测中是指:用一些比较有用的训练技巧来训练模型,从而使得模型取得更好的准确率但是不增加模型的复杂度,也就不增加推理(inference)时的计算量(cost)。在目标检测中,要进行bag of freebies。
Data augmentation
要进行Bag of Freebies,第一类方法是数据增强(Data augmentation),进行数据增强我们可以采用下面几种方法。
- 几何增强:可以采用随机翻转(一般采用水平翻转,垂直翻转采用的较少)、随即裁剪(crop)、拉伸以及旋转等方法
- 色彩增强:可以采用对比度增强、亮度增强以及HSV空间增强
以上这些Data augmentation的方式都属于pixel-wise的增强,同时我们还可以使用一些数据增强方法用来解决目标遮挡及不足的问题
- 在图像中随机裁剪矩形区域,并用0来填充(Random erase和CutOut算法)
- 随机裁剪多个矩形区域(Hide-and-seek,Grid mask)

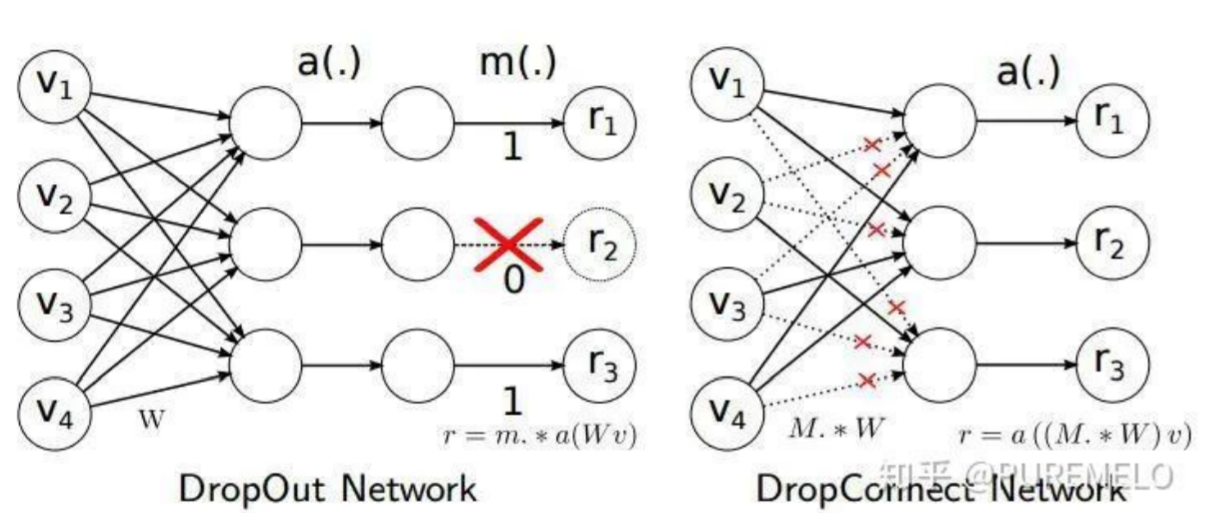
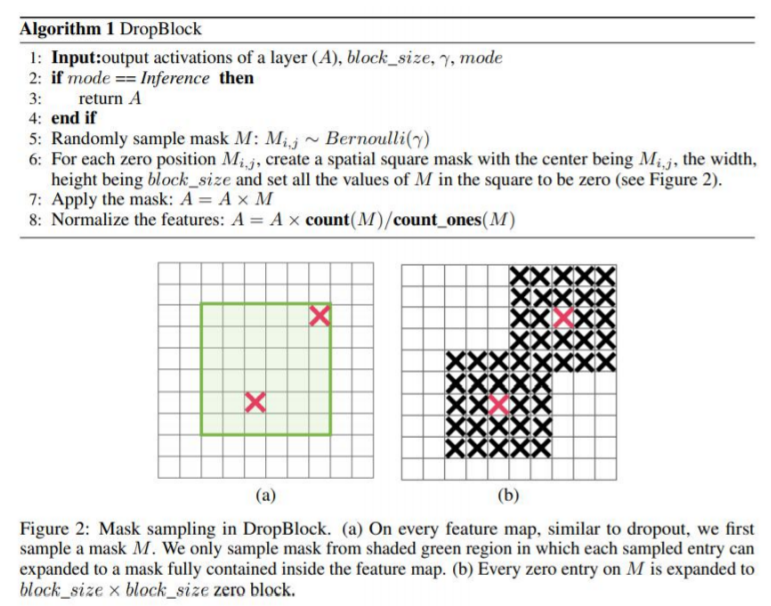
- 在feature map上裁剪并填充(DropOut,DropConnect,DropBlock)
同时,我们还可以使用Mix-Up算法、Cut-Mix算法以及Class-Label-Smoothing算法实现Data augmentation


解决不均衡问题(imbalance problems in object detection)
第二类方法主要是为了解决不均衡问题,其中包括以下几个方面
- 类别(class)不均衡: 背景和物体之间的不均衡;物体与物体之间的不均衡
- 尺度(scale)比例不均衡:object/box-level Imbalance; feature-level imbalance
- 空间(spatial)尺寸不均衡:Imbalance in regression loss; IoU Distribution Imbalance; Object Location Imbalance
- 目标函数(loss function)不均衡: Objective Imbalance
OHEM
OHEM(Online Hard Example Mining):
- HEM:用于SVM中先训练模型收敛于当前的工作集,然后固定模型,去除简单样本(能够轻易区分的),添加困难样本(不能够区分的)
- OHEM:将交替训练的步骤和 SGD 结合起来。


Focal Loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。
在one-stage的网络中,正负样本达到1:1000,这就会出现两个问题:
- 样本不平衡
- 负样本主导loss。
虽然负样本的loss小(因为大量的负样本是easy example,大量负样本是准确率很高的第0类),但个数众多,加起来的loss甚至大于了正样本的loss,从而导致了收敛不够好。
Focal Loss先解决了样本不平衡的问题,即在CE上加权重,当class为1的时候,乘以权重alpha,当class为0的时候,乘以权重1-alpha,这是最基本的解决样本不平衡的方法,也就是在loss计算时乘以权重。
ATSS
ATSS(Adaptive Training Sample Selection)能够自动根据GT的相关统计特征选择合适的anchor box作为正样本,在不带来额外计算量和参数的情况下,能够大幅提升模型的性能

改进边界框回归的目标函数
bag of freebies还通过可以改进边界框(BBox)回归的目标函数来实现。
传统的目标检测器通常使用均方误差(MSE)直接对BBox的中心点坐标以及高度和宽度执行回归,即 {xcenter, ycenter, w, h}或左上点和右下点,即{xtop_left, ytop_left, xbottom_right, ybottom_right}。
对于anchor-base的方法,将估计相应的偏移量,例如{xcenter_offset, ycenter_offset,
woffset, hoffset}和{xtop_left_offset, ytop_left_offset,
xbottom_right_offset, ybottom_right_offset}。
但是,直接估计BBox的每个点的坐标值是将这些点视为独立变量,但实际上并未考虑目标本身的完整性。为了使这个问题得到更好的处理,一些研究者最近提出了IoU loss,该方法考虑了预测的BBox区域和ground truth BBox区域的覆盖范围。
IoU loss计算过程将通过使用基本事实执行IoU,然后将生成的结果连接到整个代码中,触发BBox的四个坐标点的计算。因为IoU是尺度不变表示,所以可以解决传统方法计算{x,y,w,h}的l1或l2损失时,损失会随着尺度增加而增加的问题。
最近,一些研究人员继续改善IoU损失。例如,GioU loss除了覆盖区域外还包括对象的形状和方向。他们建议找到可以同时覆盖预测的BBox和ground truth BBox的最小面积BBox,并使用该BBox作为分母来代替最初用于IoU loss的分母。至于DIoU loss,它还考虑了目标中心的距离,而CIoU loss同时考虑了重叠区域,中心点之间的距离和纵横比。
CIoU可以在BBox回归问题上实现更好的收敛速度和准确性。
改进learning rate
改进learning rate有以下几种方法
- 等间隔(epoch)调整学习率
- 固定epoch(90,120epoch)调整学习率
- 指数衰减调整学习率 ExponentialLR: lr=lr ∗ gamma epoch
- 余弦退火调整学习率 CosineAnnealingLR:以余弦函数为周期,并在每个周期最大值时重新设置学习率。以初始学习率为最大学习率,以 2∗ Tmax2*Tmax2∗ Tmax 为周期,在一个周期内先下降,后上升。
- 自适应调整学习率 ReduceLROnPlateau
- 自定义调整学习率 LambdaLR: lr=base_lr∗lmbda(self.last_epoch)
Bag-of-Specials
什么叫做bag of specials:就是指一些plugin modules(例如特征增强模型,或者一些后处
理),这部分增加的计算量(cost)很少,但是能有效地增加物体检测的准确率,我们将这部分
称之为Bag of specials.
特征增强模型:
- 增强感受域: SPP(Spatial Pyramid Matching),ASPP(Atrous spatial pyramid pooling),RFB(Receptive Field Block)
- 引入注意力机制: Channel Attention, Spatial Attention,Channel + Spatial Attention
- 特征融合or特征集成: Skip-connection,hyper-column,multi-scale aggression
- 激活函数: ReLu, LRelu, PReLU, SELU,ReLu6, Swish, hard-Swish, Mish
后处理方法:
- NMS
- soft NMS
- DIoU NMS
NMS(非极大抑制)
NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,具体的实现思路如下:
- 选取这类box中scores最大的哪一个,记为box_best,并保留它
- 计算box_best与其余的box的IOU
- 如果其IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保留分数高的哪一个)
- 从最后剩余的boxes中,再找出最大scores的哪一个,如
此循环往复
soft NMS
soft NMS对密集物体检测的检测效果有一定的提升作用.
改进的思路为:不粗鲁地删除所有IOU大于阈值的框,而是降低其置信度。

YOLOv4相对于原先的网络额外做出的改进
为了使设计的检测器更适合在单个GPU上进行训练,YOLOv4进行了以下额外设计和改进
- 引入了一种新的数据增强Mosaic方法,以及自对抗训练(SAT)
- 在应用遗传算法时选择最佳超参数
- 修改了一些现有方法,使我们的设计适合进行有效的训练和检测-修改后的SAM,修改后的PAN和交叉mini-batch Normalization(CmBN)
Mosaic
Mosaic表示一种新的数据增强方法,该方法混合了4个训练图像。 因此,混合了4个不同的上下文(contex),而CutMix仅混合了2个输入图像。 这样可以检测正常上下文之外的目标。 此外,批量归一化从每层上的4张不同图像计算激活统计信息。 这大大减少了对大mini-batch size的需求。

SAT
自对抗训练(SAT)也代表了一项新的数据增强技术,该技术可在2个forward和backWord段进行操作。
在第一阶段,神经网络会更改原始图像,而不是网络权重。以这种方式,神经网络对其自身执行对抗攻击,从而改变原始图像以产生对图像上没有期望物体的欺骗。
在第二阶段,训练神经网络以正常方式检测此修改图像上的目标。
CmBN
CmBN表示CBN修改版本,定义为cross mini-batch normalization(CmBN)。 这仅收集单个batch中的mini-batch之间的统计信息。

SAM及PAN
将SAM从空间注意(spatial-wise attention)改为点注意(point-wise attention),并将PAN的快捷连接(shortconnection)替换为串联

YOLOv4
框架
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
具体使用
Backbone:
- BOF(Bag of Freebies):CutMix and Mosaic data augmentation; DropBlock
regularization; Class label Smoothing - BOS(Bag of Specials): Mish Activation, Cross-stage parital connections(CSP);
Multi-input weighted residual connection (MiWRC)
Detector:
- BOF: CIoU-loss; CmBN; DropBlock regularization; Mosaic
- augmentation; self-adversarial training, Eliminate grid
sensitivity; Using multiple anchors for a single ground truth,
Cosine annealing scheduler; Optimal hyper-parameters;
Random training shapes
- BOS: Mish Activation, SPP-block, SAM-block, PAN path
- block, DIoU-NMS
结果
- 开发了一个速度更快并且性能也更好的模型
- 该模型能够在8-16GB显存的显卡上训练 (因为引入了BoF和BoS)
- 该算法验证了大量的技巧
具体的效果






文章写的很好啊,赞(ㆆᴗㆆ),每日打卡~~
又发现一个好站,收藏了~以后会经常光顾的 (。•ˇ‸ˇ•。)
日常打卡~ 加油-_-|´・ω・)ノ